
Paper Fetch Skill
Fetch papers as agent-ready markdown — DOI/URL/title in, structured full text out. CLI · MCP · Skill.
Paper Fetch Skill —— 已知论文的 AI 阅读层。你有 DOI、URL 或标题;它返回结构化元数据 + 干净 Markdown 全文 + 图表资源,直接喂给 Codex / Claude Code / Gemini CLI / 任意 MCP host。不绕付费墙,只在你本就有访问权限的地方,把 AI 从「只能读摘要」升级到「读全文」。
如果觉得有帮助,欢迎 star⭐ 支持!
🙁 AI agent 读论文的痛点
- 你有权限获取全文,但 AI 没有权限,AI 只能读到摘要。
- PDF 无法正确解析文字、图片,agent 理解效果不如 markdown。
- 文章 html 有很多无关的网页信息,给 agent 造成语义负担。
- 文章 html 中的图片 agent 读不到。
😍 这个项目做什么
✅这个项目把这些问题收敛到一个工具层:
- 当你有全文获取权限时,让 AI 也能获取全文,而不仅是摘要。
- 输入 n 篇已知论文,抓取 AI 更容易理解的 markdown 版本,为后续知识库构建做好干净的数据基础。
✅项目提供三个主要入口:
paper-fetch:命令行工具,适合手动大规模快速抓取文献。paper-fetch-mcp:stdio MCP server,适合接入 Codex、Claude Code、Gemini CLI 等支持 MCP 的 host。skills/paper-fetch-skill/:静态 agent skill,告诉 agent 什么时候应该调用论文抓取工具。
核心能力:
- 支持 DOI、URL 和标题查询。
- 输出结构化论文元数据、正文 Markdown、引用信息和本地缓存资源。
- 支持常见 provider 路由,包括 Crossref、arXiv、Elsevier、Springer、Wiley、Science、PNAS、AMS、ACS、IEEE、MDPI 和 Copernicus。
- 在无法取得全文时返回带 warning 的 abstract-only 或 metadata-only 结果。
项目边界:
- 不做主题检索、文献推荐或综述生成。
- 不绕过付费墙或访问授权;可用性取决于 provider、凭据和本机运行环境。
- Wiley、Science、PNAS、AMS、ACS、MDPI 的浏览器路径统一使用 CloakBrowser;IEEE 路线不需要额外 API key,但全文可用性取决于 IEEE Xplore 对当前环境的合法访问上下文。
- Provider onboarding 的 AI/coordinator 自动化入口见
onboarding/README.md,其中的 runner 仍不能代替 access approval、challenge 决策或最终语义审查判断;最终签字由用户确认后通过项目脚本机械写入。
效果展示
agent 安装 skill 后,可以识别 paper-fetch-skill 的适用边界,并在抓取前确认是否保存全文和图表资源。
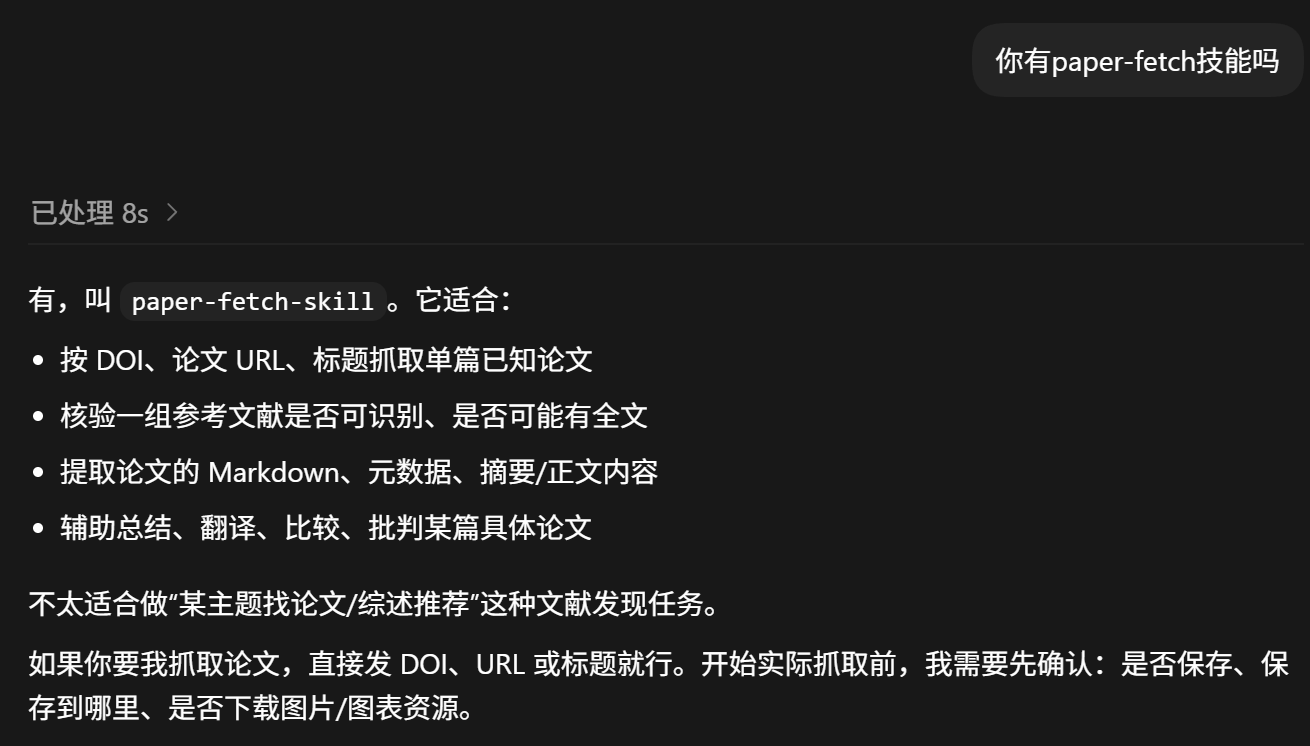
以下示例来自 figures/ 中的真实开放抓取产物。
Nature 示例
- 论文:Towards end-to-end automation of AI research
- DOI:
10.1038/s41586-026-10265-5 - 来源:Springer/Nature HTML full text
- 许可:
CC BY 4.0 - Markdown 全文:
towards-end-to-end-automation-of-ai-research.md

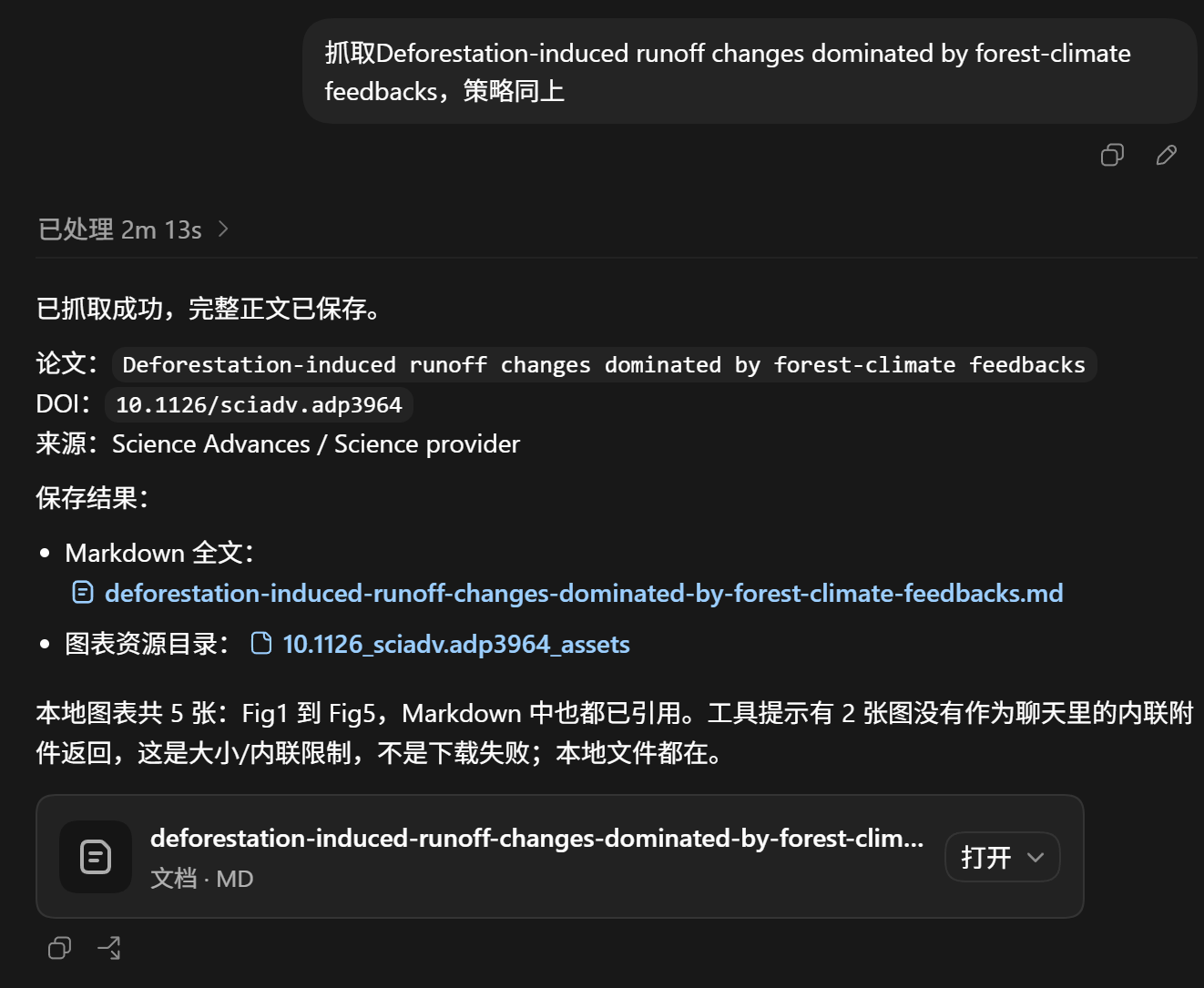
Science Advances 示例
- 论文:Deforestation-induced runoff changes dominated by forest-climate feedbacks
- DOI:
10.1126/sciadv.adp3964 - 来源:Science Advances / Science provider
- Markdown 全文:
deforestation-induced-runoff-changes-dominated-by-forest-climate-feedbacks.md
快速安装
离线安装(推荐)
离线 release asset 包含 4 个 Linux ABI 自解压 .sh 安装器、4 个 macOS ABI tarball 和 1 个 Windows x86_64 安装器。macOS tarball 使用同一构建脚本在 macos-latest 上按 runner 架构和 CPython 3.11、3.12、3.13、3.14 生成,并由 macOS CI 验证安装、headful preset 和 CloakBrowser 浏览器启动 smoke。
paper-fetch-skill-offline-linux-x86_64-cp311.sh
paper-fetch-skill-offline-linux-x86_64-cp312.sh
paper-fetch-skill-offline-linux-x86_64-cp313.sh
paper-fetch-skill-offline-linux-x86_64-cp314.sh
paper-fetch-skill-offline-macos-<arch>-cp311.tar.gz
paper-fetch-skill-offline-macos-<arch>-cp312.tar.gz
paper-fetch-skill-offline-macos-<arch>-cp313.tar.gz
paper-fetch-skill-offline-macos-<arch>-cp314.tar.gz
paper-fetch-skill-windows-x86_64-setup.exe
I. Windows x86_64:
1. 下载安装包
在 Releases 中下载
paper-fetch-skill-windows-x86_64-setup.exe
2. 双击安装或者在本地终端运行安装程序
.\paper-fetch-skill-windows-x86_64-setup.exe
安装器默认安装到 %LOCALAPPDATA%\PaperFetchSkill,不要求管理员权限。会自动安装 paper-fetch CLI 工具、注册 MCP 并安装 Skill。若用户级 PATH / Skill / MCP 集成或 smoke check 在本机失败,runtime 仍会保留在安装目录,详细警告见 %LOCALAPPDATA%\PaperFetchSkill\install-helper.log。
3. 验证安装
安装后新开一个 PowerShell
paper-fetch --help
如果有输出usage: cli.py [-h] -(后略)则安装成功
4. 开启 Wiley / Science / PNAS / AMS / ACS / MDPI 浏览器路径
安装器会注册 CloakBrowser 默认 headless 环境,并在 offline.env 默认启用普通 Chrome browser UA,降低 AGU/Wiley 页面进入 Cloudflare challenge 的概率。受限环境可在 offline.env 中设置 CLOAKBROWSER_BINARY_PATH 指向预装浏览器;如果 GUI/WSLg 环境下仍被 challenge,再把 CLOAKBROWSER_HEADLESS=false,安装 Linux .sh 时使用 --preset=wslg,或在 macOS 离线 bundle 中使用 --preset=headful。Windows 安装器还会设置 MATHML_TO_LATEX_NODE_BIN 指向包内 Playwright Node,避免 Codex Desktop 的 WindowsApps/MSIX 内部 node.exe 被公式转换 fallback 误用。
5. 开启 Elsevier 获取权限
Elsevier 官方 XML/API 和 PDF fallback 需要从 https://dev.elsevier.com/ 申请 key,并写入安装目录下的 offline.env:
notepad "$env:LOCALAPPDATA\PaperFetchSkill\offline.env"
6. 刷新 agent skill
修改 Codex / Claude Code / Gemini CLI skill、MCP 配置或 offline.env 后需要重启对应 host;已经启动的 MCP 服务不会自动继承新环境变量。
7. 常见问题
Windows 安装器和离线安装细节见 docs/deployment.md。
II. Linux
1. 下载安装包
检查python版本
python3 --version
在 Releases 中选择与目标机 Python 版本的包下载。
paper-fetch-skill-offline-linux-x86_64-cp311.sh
paper-fetch-skill-offline-linux-x86_64-cp312.sh
paper-fetch-skill-offline-linux-x86_64-cp313.sh
paper-fetch-skill-offline-linux-x86_64-cp314.sh
Linux .sh 是自解压安装器,内部 payload 是预安装 runtime 包,不再是源码快照。默认安装到 ~/.local/share/paper-fetch-skill,也可以用 --install-dir <path> 指定固定目录。
Ubuntu 24.04 系统默认 Python 版本 3.12,Ubuntu 26.04 为 3.14。
直接执行安装器:
chmod +x paper-fetch-skill-offline-linux-x86_64-cp312.sh
./paper-fetch-skill-offline-linux-x86_64-cp312.sh --preset=headless --no-user-config
source ~/.local/share/paper-fetch-skill/activate-offline.sh
WSLg 或桌面显示环境可改用:
./paper-fetch-skill-offline-linux-x86_64-cp312.sh --preset=wslg --no-user-config
如需固定到自定义目录:
./paper-fetch-skill-offline-linux-x86_64-cp312.sh --install-dir "$HOME/tools/paper-fetch-skill" --preset=headless --no-user-config
source "$HOME/tools/paper-fetch-skill/activate-offline.sh"
Linux / macOS 离线安装会优先把 MATHML_TO_LATEX_NODE_BIN 指向包内 Playwright Node,避免依赖系统 PATH 上的 node;生成的 activate-offline.sh 可在 bash 或 zsh 中 source。
macOS 离线 release asset 按 CPython ABI 提供 tarball;下载与目标机架构和 Python 版本匹配的 paper-fetch-skill-offline-macos-*-cp*.tar.gz 后解压运行。macOS 可见浏览器调试使用:
tar -xzf paper-fetch-skill-offline-macos-arm64-cp312.tar.gz
cd paper-fetch-skill-offline-macos-arm64-cp312
./install-offline.sh --preset=headful --no-user-config
source ~/.local/share/paper-fetch-skill/activate-offline.sh
III. 更新和卸载
更新
Windows 下载新版 paper-fetch-skill-windows-x86_64-setup.exe 后直接运行。安装器会先备份 %LOCALAPPDATA%\PaperFetchSkill\offline.env,清理旧安装 payload,再安装新版运行时并写回用户配置,只刷新受管理的运行时配置、PATH、Skill 和 MCP 注册。
Linux 下载与目标机 Python 版本匹配的新版 .sh 后直接运行。默认安装目录固定为 ~/.local/share/paper-fetch-skill,升级时会清理旧 runtime payload、移除旧源码/构建残留,并保留安装目录内的 offline.env。若希望复用外部 env 文件且不修改它,使用 --reuse-env-file:
./paper-fetch-skill-offline-linux-x86_64-cp312.sh --preset=headless --no-user-config
./paper-fetch-skill-offline-linux-x86_64-cp312.sh --preset=headless --no-user-config --reuse-env-file /path/to/shared/offline.env
source ~/.local/share/paper-fetch-skill/activate-offline.sh
--reuse-env-file 会让 shell / Skill / MCP 指向新版 runtime,但不会修改被复用的 offline.env。更新后重启 Codex / Claude Code / Gemini CLI。
卸载
Windows 在“设置 > 应用 > 已安装的应用”中卸载 Paper Fetch Skill,或运行:
& "$env:LOCALAPPDATA\PaperFetchSkill\unins000.exe"
如需保留 offline.env 中的 API key,卸载前先备份该文件。
Linux 默认安装目录运行:
~/.local/share/paper-fetch-skill/install-offline.sh --uninstall
该命令只清理用户级 PATH / Skill / MCP 集成,不删除固定安装目录、bin/、runtime/、offline.env 或 downloads/;确认不再需要后运行 ~/.local/share/paper-fetch-skill/install-offline.sh --purge 删除安装目录。
在线安装(不推荐,开发使用)
在仓库根目录执行:
./install.sh
默认会创建仓库内 .venv,安装 Python 包,并准备 CloakBrowser 依赖和公式后端等运行组件。
如果只想安装 Python 包和基础配置:
./install.sh --lite
arXiv 路径细节见 docs/providers.md。
如果只想装进当前 Python 环境:
python3 -m pip install .
安装后可用命令:
paper-fetch --query "10.1186/1471-2105-11-421"
paper-fetch-mcp
CLI 行为速查
paper-fetch 的输出与本地 artifact 参数分工如下:
--format markdown|json|both指定 stdout、--output或--output-dir默认主输出文件的序列化格式,默认是markdown。--query-file <path>启用批量抓取,每行一个 DOI、URL 或标题;空行和以#开头的注释行会被忽略。批量模式不向 stdout 输出正文,而是把每篇主输出写到输出目录,并生成 JSONL 汇总。--output <path>把这份格式化结果写到指定文件;显式--output -表示打印到终端。--output-dir <dir>是默认主输出、Markdown、PDF fallback 来源文件和本地资产的保存目录;CLI 会在抓取前自动创建该目录,未显式传--output时,主输出会写到<doi>.md、<doi>.json或<doi>.both.json,不再把正文打印到终端。--batch-concurrency <1..8>控制批量并发,默认1;--batch-results <path>可覆盖默认的<output-dir>/batch-results.jsonl。--artifact-mode markdown-assets|all|none控制中间产物保留,CLI 默认是markdown-assets:保存 Markdown、按--asset-profile保存资产,不保留 provider 原始 HTML/XML、fetch-envelope/cache JSON 或 HTTP textual cache;如果正文来自 PDF fallback,仍会保存 PDF 源文件便于溯源。--artifact-mode all保留旧行为:provider HTML/PDF、辅助 artifact、HTTP textual cache 等调试 artifact 都可落盘。--artifact-mode none不保存 provider artifact 或资产;显式--output <path>、--save-markdown,以及未显式--output时由--output-dir承接的主输出仍可写文件。--no-download保留兼容,但已弃用,等价于--artifact-mode none。--asset-profile none|body|all控制本地内容资产下载范围,CLI 默认是body:none不下载本地资产但保留 Markdown 中可解析的远程图片链接,body保存正文图片/图表/公式图片,all额外保存补充材料。
完整命令组合、主输出与 artifact 的区别、错误输出和 exit code 见 docs/cli.md。
例如:
paper-fetch --query "https://www.nature.com/articles/s41559-026-03039-9" \
--output-dir ./papers
这会把 Markdown 写到 ./papers/<doi>.md,不打印正文到终端,并按默认 --asset-profile body 保存正文图片等资产;默认不会保存 provider 原始 HTML/XML 或 JSON/cache sidecar。需要完整调试 artifact 时显式使用 --artifact-mode all。如果需要强制打印到终端,显式传 --output -。
批量抓取时先准备 query 文件:
# 每行一个 DOI、URL 或标题
10.1186/1471-2105-11-421
https://www.nature.com/articles/s41559-026-03039-9
然后运行:
paper-fetch --query-file ./queries.txt \
--output-dir ./papers \
--batch-concurrency 4
这会把每篇 Markdown 和正文资产写到 ./papers,并生成 ./papers/batch-results.jsonl。单篇失败会记录到 JSONL 并继续处理后续条目。
如果只想控制格式化结果的文件路径,显式使用 --output:
paper-fetch --query "10.1186/1471-2105-11-421" \
--format markdown \
--output ./papers/article.md \
--output-dir ./papers
显式 --output <path> 只控制主输出文件路径,不会自动创建该文件的父目录。
安装脚本结束时会提示 Elsevier 官方 API 配置入口。抓取 Elsevier 全文前,需要从 https://dev.elsevier.com/ 申请 key,并在配置文件中填写 ELSEVIER_API_KEY。
配置文件
默认配置文件位置:
~/.config/paper-fetch/.env
需要 API key、自定义下载目录或 User-Agent 时,可以先创建配置文件:
mkdir -p ~/.config/paper-fetch
cp .env.example ~/.config/paper-fetch/.env
其中 Elsevier 官方 XML/API 和 PDF fallback 至少需要从 https://dev.elsevier.com/ 申请并配置:
ELSEVIER_API_KEY="..."
也可以通过环境变量显式指定:
export PAPER_FETCH_ENV_FILE=/path/to/.env
完整环境变量说明见 docs/providers.md。
接入 Codex
安装 skill 并注册 MCP server:
./scripts/install-codex-skill.sh --register-mcp
带配置文件注册:
./scripts/install-codex-skill.sh --register-mcp --env-file ~/.config/paper-fetch/.env
只安装到当前项目:
./scripts/install-codex-skill.sh --project --register-mcp
安装后重启 Codex,让它重新扫描 skills 和 MCP 配置。
接入 Claude Code
./scripts/install-claude-skill.sh --register-mcp
常用参数包括:
./scripts/install-claude-skill.sh --project --register-mcp
./scripts/install-claude-skill.sh --register-mcp --env-file ~/.config/paper-fetch/.env
接入 Gemini CLI
安装 skill 并注册 MCP server:
./scripts/install-gemini-skill.sh --register-mcp
带配置文件注册:
./scripts/install-gemini-skill.sh --register-mcp --env-file ~/.config/paper-fetch/.env
只安装到当前项目:
./scripts/install-gemini-skill.sh --project --register-mcp
如果本机没有 gemini CLI,脚本会安装 skill 并跳过自动 MCP 注册;安装 Gemini CLI 后可重跑同一命令。
手动注册 MCP
任何支持 stdio MCP 的 host 都可以直接运行:
paper-fetch-mcp
或:
python3 -m paper_fetch.mcp.server
Gemini CLI 可手动注册同一个 stdio server:
gemini mcp add -s user paper-fetch python3 -m paper_fetch.mcp.server
WSL 下给 Codex 挂 MCP 时,推荐使用仓库包装脚本:
./scripts/run-codex-paper-fetch-mcp.sh
常用抓取参数
MCP 默认模式、artifact_mode、prefer_cache、no_download 和 save_markdown 的完整语义见 docs/providers.md。MCP artifact_mode 默认是 markdown-assets;strategy.asset_profile 支持 none、body、all,MCP/Python API 未显式设置时默认由 provider 决定。
更新
更新仓库后重新安装包和 agent 集成:
python3 -m pip install .
./scripts/install-codex-skill.sh --register-mcp
Claude Code 用户对应执行:
./scripts/install-claude-skill.sh --register-mcp
Gemini CLI 用户对应执行:
./scripts/install-gemini-skill.sh --register-mcp
文档
docs/deployment.md:安装、配置、MCP 注册和更新。docs/providers.md:provider 能力、环境变量和运行时配置。docs/README.md:完整文档导航。docs/architecture/overview.md:架构边界和维护者视角。
免责声明
本项目通过公开可访问的开放获取接口、publisher 路由和用户配置的凭据获取研究论文内容。
- 获取的文献仅供个人学术研究和学习使用,不得用于商业用途。
- 请遵守所在国家/地区著作权法律法规及所在机构的知识产权政策。
- 本项目不绕过付费墙或访问授权;可用性取决于 provider、凭据和本机运行环境。
- 本项目不存储、分发或传播任何文献内容,仅协助用户定位、抓取或转换用户有权访问的论文内容。
- 使用者应对自身的文献获取和使用行为承担全部责任。