
MCP Speaker Diarization
![]()
![]()
![]()
An all-in-one complete package combining GPU-accelerated speaker diarization and recognition with web interface and REST API. Integrates pyannote.audio speaker diarization with faster-whisper transcription, designed for AI agent integration and hobby projects.
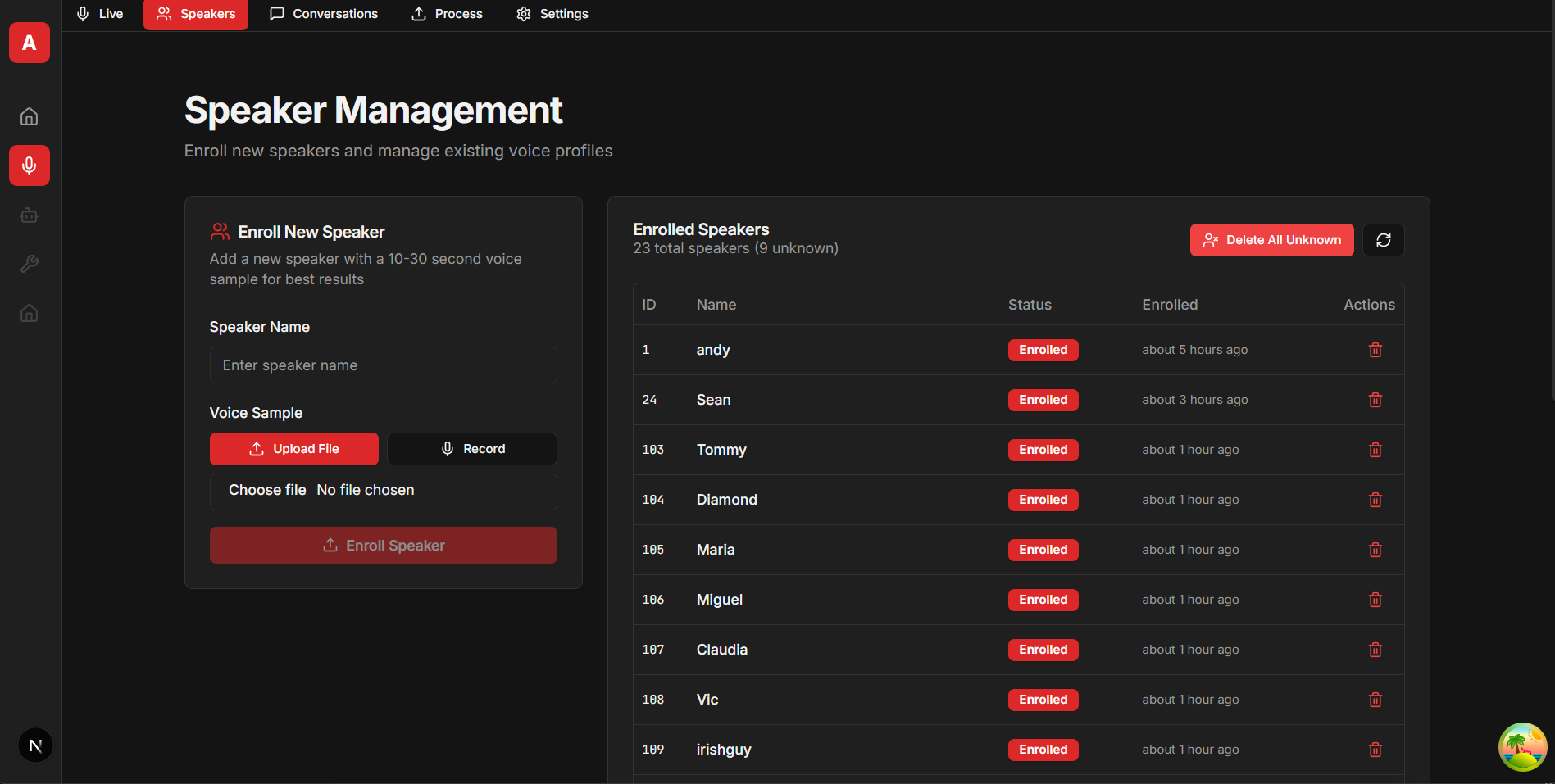
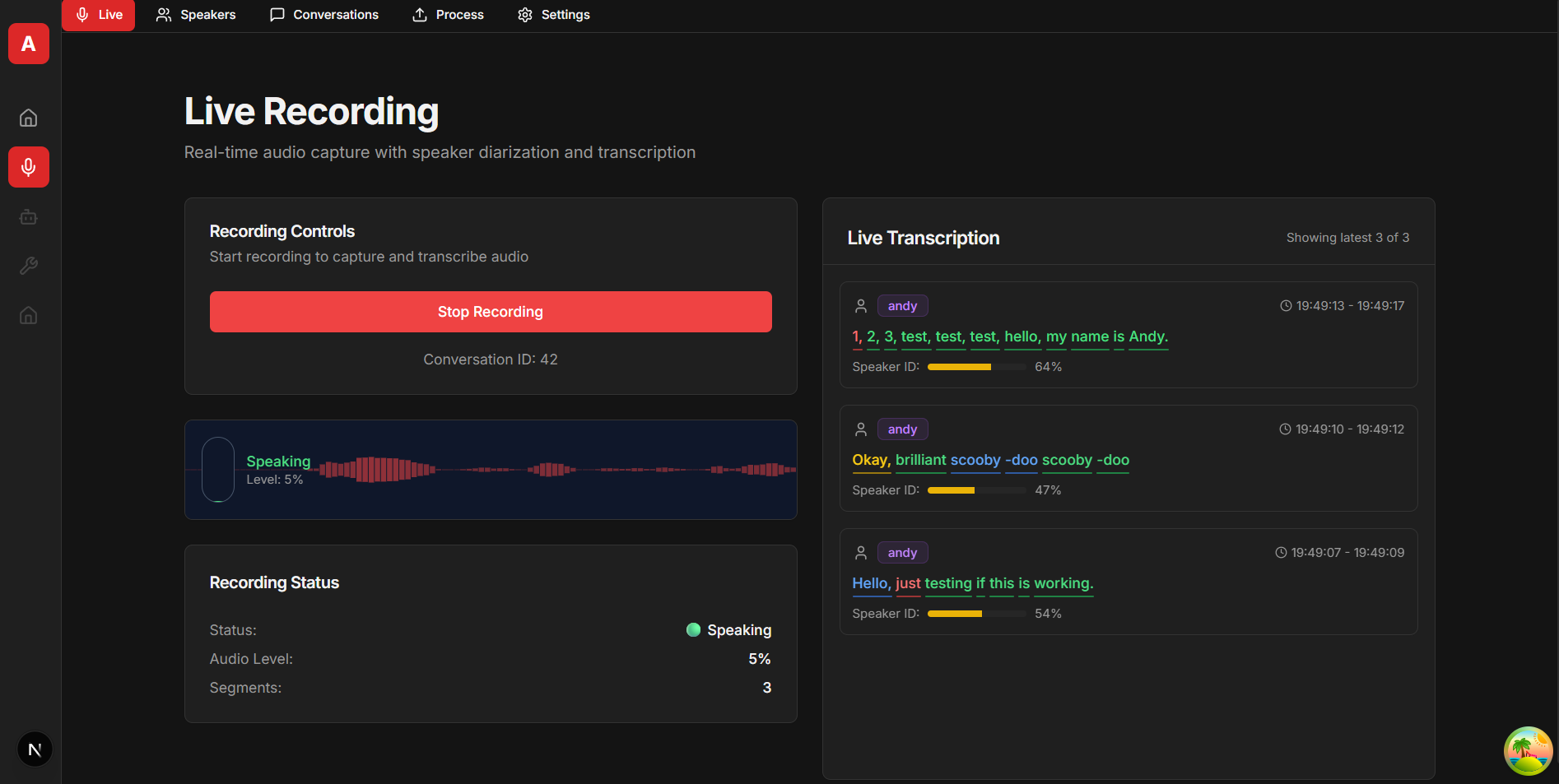
Screenshots
Example Next.js frontend interface (available at github.com/snailbrainx/speaker_identity_nextjs):
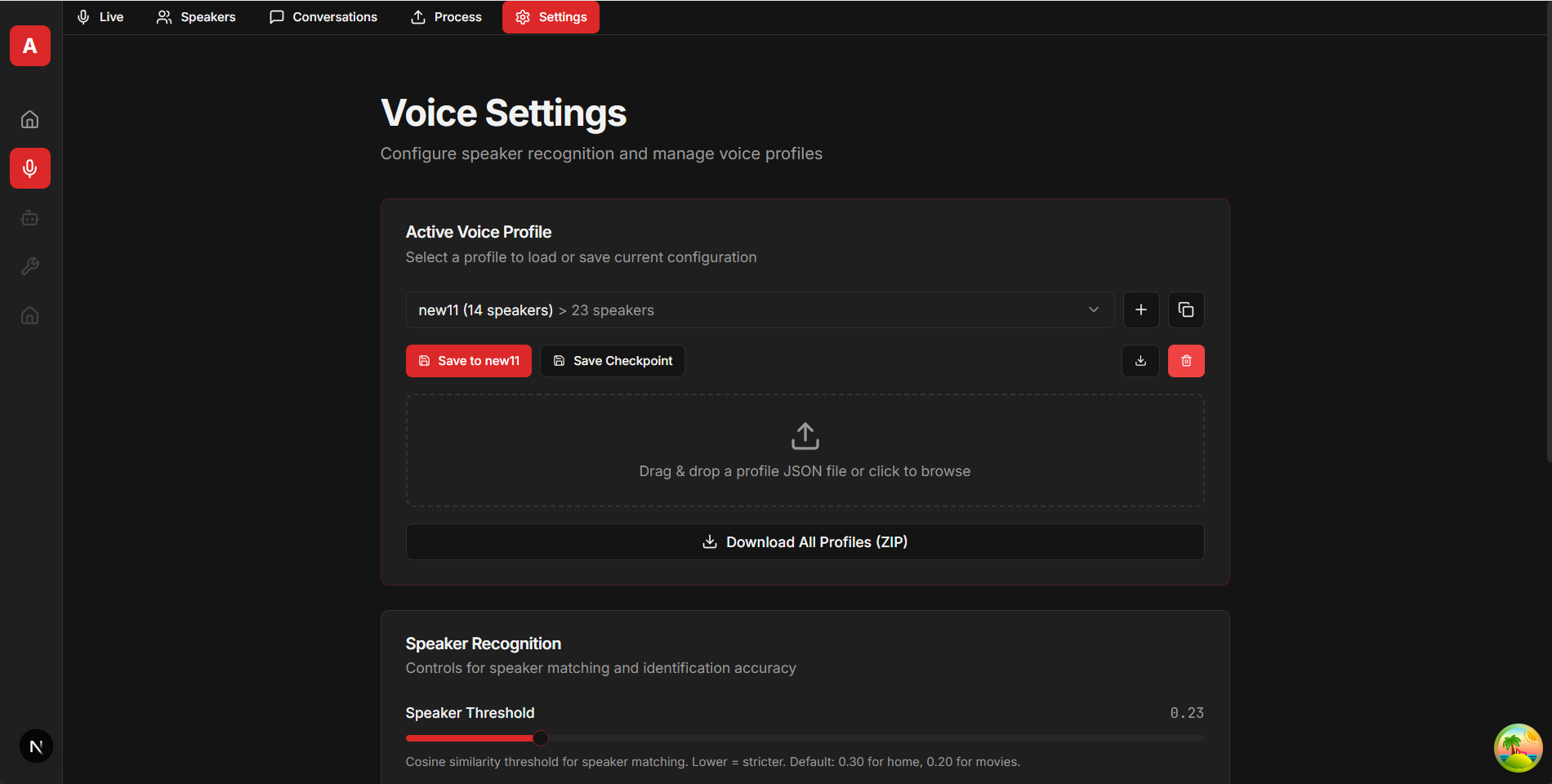{kind=link}
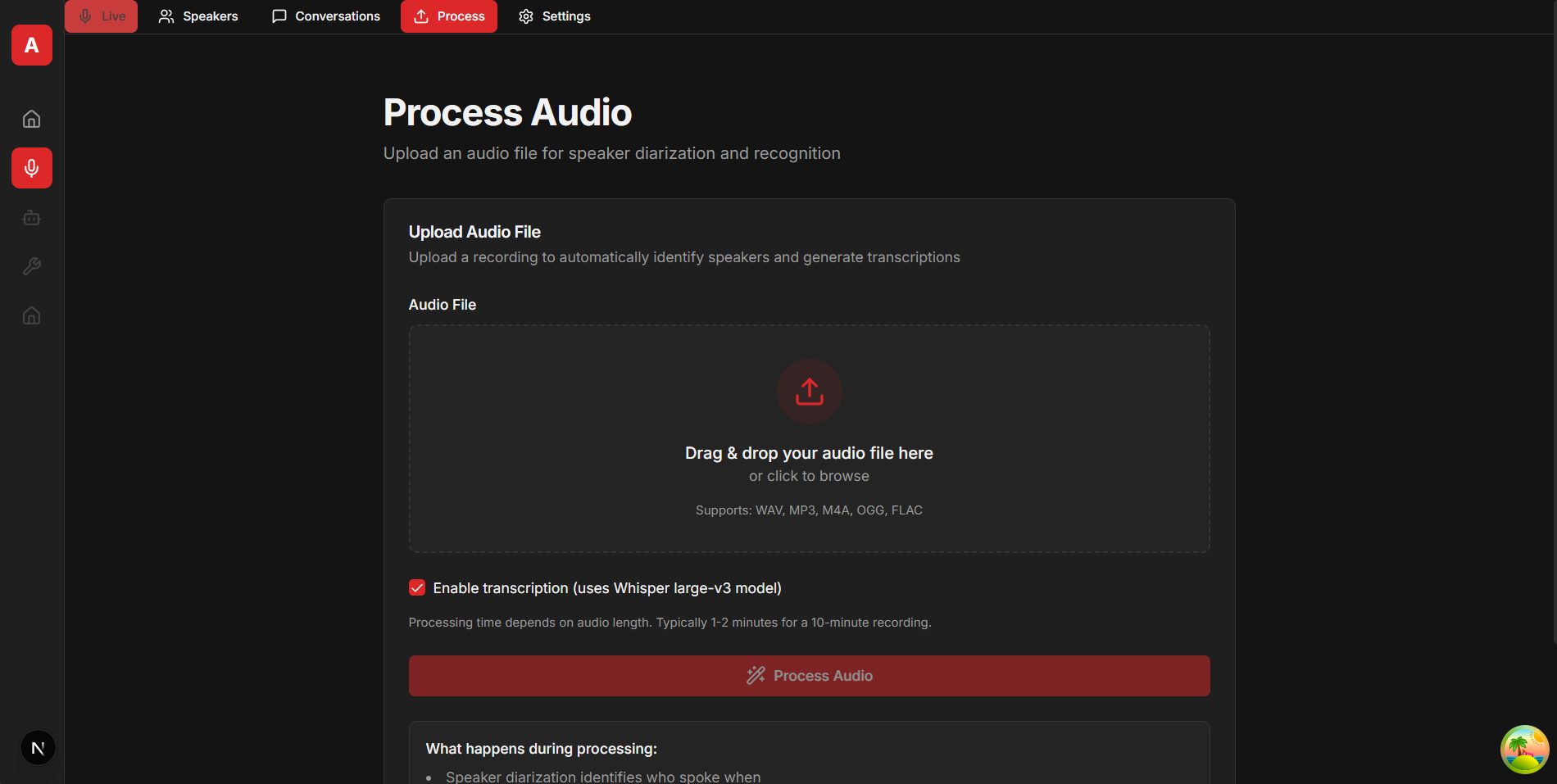{kind=link}
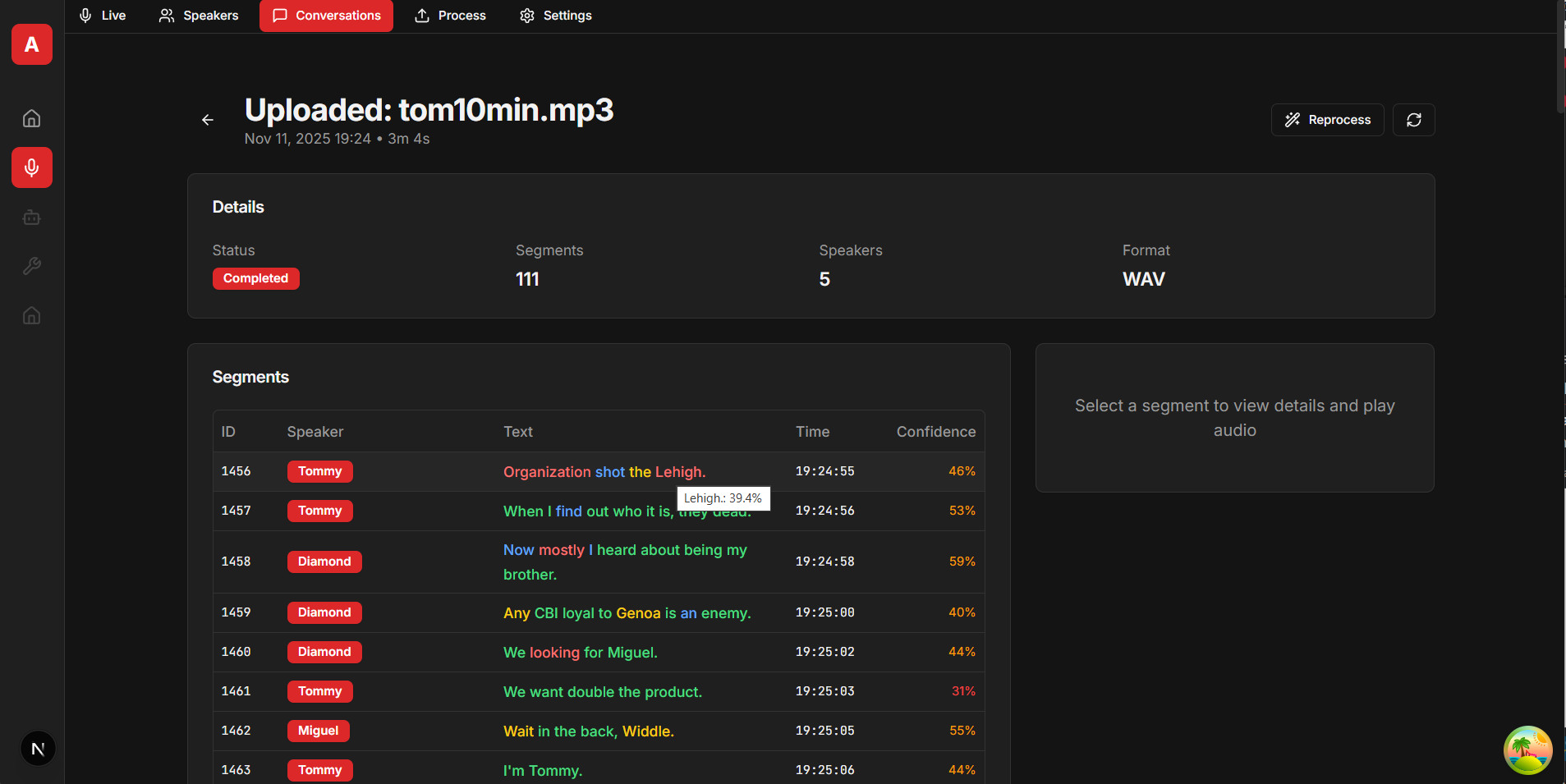{kind=link}
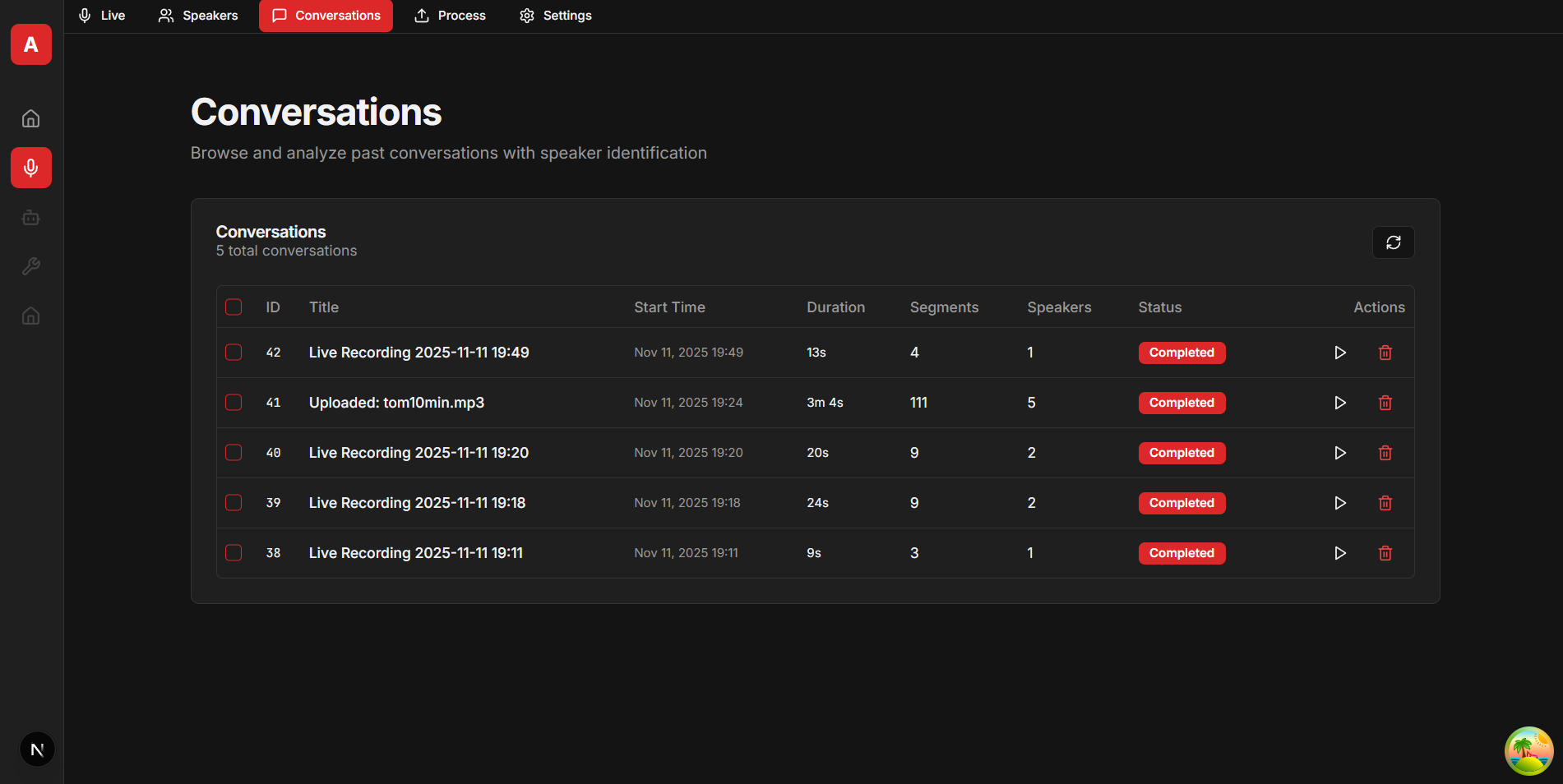{kind=link}
{kind=link}
{kind=link}
Key Features
- Persistent Speaker Recognition: Enroll speakers once, recognize them across all future recordings and conversations (not just "SPEAKER_00, SPEAKER_01" labels)
- Dual-Detector Emotion System: Combines general AI (emotion2vec+) with personalized voice profiles for dramatically improved emotion detection accuracy across 9 emotions (angry, happy, sad, neutral, fearful, surprised, disgusted, other, unknown)
- Personalized Learning: System learns each speaker's unique emotional voice patterns from corrections with weighted embedding merging (no re-enrollment needed)
- Retroactive Intelligence: Identify one segment → all past segments with that voice automatically update
- Transcription: faster-whisper (large-v3) with word-level confidence scores and 99 language support
- Live Streaming: Real-time recording with WebSocket streaming, VAD, and instant processing
- AI-Ready Architecture: Built-in MCP server enables seamless integration with AI assistants (Claude Desktop, Flowise, custom agents) providing the contextual memory needed for natural multi-party conversations
- REST API: Full programmatic access at
/api/v1/*(see/docsfor interactive documentation) - Backup/Restore: Export/import speaker profiles and voice settings
- Production Ready: Handles thousands of conversations, batch processing, live streaming, MP3 conversion, and scales efficiently
Use Cases
AI Integration: Enable AI assistants to remember and distinguish multiple speakers across conversationsMeeting Transcription: Automatic labeling with emotion contextResearch & Analysis: Multi-party conversation analysis with persistent identityCustomer Support: Separate agents from customers with emotion tracking
Technical Stack
- Diarization: pyannote.audio 4.0.1 (
pyannote/speaker-diarization-community-1) - Embeddings: pyannote.audio (
pyannote/embedding) - Emotion Recognition: emotion2vec_plus_large via FunASR (ACL 2024, 9 emotion categories)
- Transcription: faster-whisper 1.2.1 (configurable models: tiny/base/small/medium/large-v3, supports 99 languages, CTranslate2 backend)
- Backend API: FastAPI 0.115.5 with WebSocket streaming support
- ML Framework: PyTorch 2.5.1 with CUDA 12.4 support
- Database: SQLAlchemy 2.0.36 with SQLite + Pydantic 2.11.0
- Audio Processing: pydub, soundfile, ffmpeg
- MCP Integration: MCP 1.21.0 for AI agent connectivity
Emotion Detection
Dual-detector system combining general AI with personalized voice profiles for dramatically improved accuracy.
How It Works
Two complementary detectors work together:
emotion2vec+ Detector (1024-D emotion embeddings)
- General emotion AI trained on large datasets
- Works for all speakers (known/unknown)
- 9 categories: angry, happy, sad, neutral, fearful, surprised, disgusted, other, unknown
Voice Profile Detector (512-D speaker embeddings)
- Learns each speaker's unique emotional voice patterns
- Requires 3+ voice samples per emotion to activate
- Checks general + all emotion-specific profiles (Andy, Andy_angry, Andy_happy, etc.)
Best match wins: If Andy_angry voice profile matches at 92% vs emotion2vec's 78% neutral, voice detector wins.
Threshold Configuration
Environment Variables:
EMOTION_THRESHOLD=0.6- Emotion matching sensitivity (0.3-0.9, higher = stricter)SPEAKER_THRESHOLD=0.30- Voice matching sensitivity (0.20-0.35, higher = stricter)
Both thresholds can be customized per-speaker or per-emotion via the API for fine-grained control.
Personalized Learning
Correct any segment's emotion → system learns automatically:
- Stores emotion embedding (1024-D) for emotion2vec matching
- Stores voice embedding (512-D) for voice profile matching
- Merges using weighted averaging (older samples have more weight)
- Updates general speaker profile too
- After 3+ corrections per emotion → voice detector activates
Manual correction = 100% confidence. No need to re-identify speaker.
Performance
- Speed: ~37ms per segment (+5ms for voice matching)
- VRAM: ~2GB emotion2vec + ~1GB speaker embeddings (shared)
- Activation: 3+ voice samples required per emotion
System Requirements
Hardware
- GPU: NVIDIA GPU with CUDA 12.x support
- Tested on: NVIDIA RTX 3090 (24GB VRAM) - excellent performance
- VRAM Requirements (faster-whisper is very efficient):
- Diarization + embeddings: ~2-3GB base requirement
- Emotion detection: ~2GB (emotion2vec_plus_large)
- Whisper model adds (choose based on available VRAM):
tiny/base: ~400-500MB (total: ~5GB minimum with emotion)small: ~1GB (total: ~6GB recommended with emotion)medium: ~2GB (total: ~7GB recommended with emotion)large-v3: ~3-4GB (total: ~8-9GB recommended with emotion, default)
- Works on: Consumer GPUs (GTX 1060 6GB+, 1080, 2060, 3060, 3090, 4080, 4090, etc.)
- CPU Fallback: Runs on CPU but significantly slower (GPU strongly recommended)
- RAM: 8GB minimum, 16GB+ recommended
- Storage: ~10GB for models, plus space for audio recordings
Software
- Operating System: Linux (tested on Ubuntu), macOS (via Docker), Windows (via WSL2 + Docker)
- Python: 3.11 or 3.12
- CUDA: 12.4 (included in Docker image)
- cuDNN: 9.x (auto-installed)
- Docker (optional but recommended): 20.10+ with NVIDIA Container Toolkit
System Dependencies
- ffmpeg: Audio processing and format conversion
- git: HuggingFace model downloads
- portaudio19-dev: Live microphone recording (optional)
Quick Start
Prerequisites
Get a HuggingFace Token
- Create account at huggingface.co
- Generate token at huggingface.co/settings/tokens
- Accept model terms:
Install NVIDIA Container Toolkit (Docker deployment)
# Ubuntu/Debian distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker
Option 1: Docker Deployment (Recommended)
# Clone repository
git clone <repository-url>
cd speaker-diarization-app
# Configure environment
cp .env.example .env
# Edit .env and add your HF_TOKEN
# Build and run
docker-compose up --build
# Run in background
docker-compose up -d
# View logs
docker-compose logs -f
Access the application:
- API Documentation: http://localhost:8000/docs
- API Endpoint: http://localhost:8000/api/v1
- MCP Server: http://localhost:8000/mcp
For a web interface, see the separate Next.js frontend repository.
Option 2: Local Development (Python venv)
# Install system dependencies
sudo apt-get update
sudo apt-get install -y ffmpeg git portaudio19-dev
# Setup Python environment
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install Python packages
pip install -r requirements.txt
# Configure environment
cp .env.example .env
# Edit .env and add your HF_TOKEN
# Run application
./run_local.sh
# Or run manually:
# export HF_TOKEN="your_token_here"
# python -m app.main
First Run:
- Models will auto-download (~3-5GB)
- Startup may take 2-3 minutes for model loading
- GPU memory will be allocated (check with
nvidia-smi)
Remote Access
If you're running the application on a remote server (e.g., headless Ubuntu server with GPU), you can access the web interface via SSH port forwarding.
SSH Tunnel (Windows)
Using PowerShell or Command Prompt:
ssh -L 8000:localhost:8000 username@remote-server-ip
Using PuTTY:
- Open PuTTY and enter your server hostname/IP
- Navigate to: Connection → SSH → Tunnels
- Add forwarding rule:
- Source port:
8000 - Destination:
localhost:8000 - Click "Add"
- Source port:
- Return to Session tab and connect
After connecting:
- Open browser on your Windows machine
- Navigate to:
http://localhost:8000/docs(API documentation)
SSH Tunnel (Linux/Mac)
ssh -L 8000:localhost:8000 username@remote-server-ip
Then access API docs at http://localhost:8000/docs.
Important Notes
- Security Warning: This application has no built-in authentication or encryption. Do NOT expose it on open/public networks. Only use on trusted local networks or via SSH tunneling.
- The SSH connection must remain open while using the application
- All audio processing happens on the remote server (utilizes remote GPU)
- Your local machine only displays the web interface
- Microphone recording uses your local browser's microphone, uploads to server
- For network deployments, consider proper HTTPS with nginx reverse proxy and authentication
Configuration
All settings are configured via environment variables in .env file:
Required
# HuggingFace token for model access
HF_TOKEN=your_huggingface_token_here
Optional (with optimized defaults)
# Database location
DATABASE_URL=sqlite:////app/volumes/speakers.db
# Speaker recognition threshold (0.0-1.0)
# Lower = more strict, fewer false positives
# Recommended: 0.30 for normal home usage (good balance of accuracy and matching)
# Alternative: 0.20 for stricter matching with movie audio/background music
SPEAKER_THRESHOLD=0.30
# Context padding for embedding extraction (seconds)
# Adds time before/after segment for robust embeddings
# Optimal: 0.15s (67.4% matching + only 3 misidentifications in movie audio)
CONTEXT_PADDING=0.15
# Silence duration before processing segment (seconds)
# For live recording only
# Lower = more responsive, Higher = more complete segments
SILENCE_DURATION=0.5
# Filter common Whisper hallucinations
# Set to false if real speech is being filtered
FILTER_HALLUCINATIONS=true
# Global emotion matching threshold (0.3-1.0)
# Higher = stricter matching (requires closer match to learned emotion profile)
# Lower = more lenient (accepts wider range of emotional expressions)
# Default: 0.6 (balanced - good for most use cases)
EMOTION_THRESHOLD=0.6
# Whisper transcription model (faster-whisper with CTranslate2)
# Choose based on GPU capabilities:
# - tiny.en / tiny: ~400MB VRAM, fastest, lowest accuracy
# - base.en / base: ~500MB VRAM, very fast, basic accuracy
# - small.en / small: ~1GB VRAM, fast, good accuracy
# - medium.en / medium: ~2GB VRAM, slower, better accuracy
# - large-v3 / large-v2: ~3-4GB VRAM, slowest, best accuracy
WHISPER_MODEL=large-v3
# Whisper language setting
# - "en" = English only (default, fastest)
# - "auto" = Auto-detect language (99 languages supported)
# - Or specify: "es", "fr", "de", "zh", "ja", etc.
WHISPER_LANGUAGE=en
Recommended Settings
Default settings are optimized for normal home usage:
- SPEAKER_THRESHOLD=0.30: Good balance of accuracy and matching for home conversations
- CONTEXT_PADDING=0.15: Optimal for audio with background noise/music
- SILENCE_DURATION=0.5: Balances responsiveness with complete sentence capture
- WHISPER_MODEL=large-v3: Best accuracy, requires ~3-4GB VRAM. Use
small(~1GB) orbase(~500MB) for weaker GPUs. - WHISPER_LANGUAGE=en: English only (fastest). Use
autofor multilingual auto-detection or specify language code.
For stricter matching with movie audio or challenging conditions, reduce SPEAKER_THRESHOLD to 0.20.
How It Works
Architecture Overview
┌──────────────────────────────────────────────────────────────────┐
│ User Input │
│ (Upload Audio / Live Recording) │
└──────────────────────────┬───────────────────────────────────────┘
│
▼
┌───────────────────────┐
│ Audio Format │
│ Conversion │
│ (if needed) │
│ │
│ MP3/M4A → WAV │
│ Live: 48kHz chunks │
└───────────┬───────────┘
│
╔══════════════╧════════════════╗
║ PARALLEL PROCESSING ║ ← ~50% faster!
║ ThreadPoolExecutor ║ Both run
║ (2 workers) ║ simultaneously
╚══════════════╤════════════════╝
│
┌─────────────────┴─────────────────┐
│ │
▼ ▼
┌────────────────────┐ ┌───────────────────────┐
│ Transcription │ │ Diarization │
│ (faster-whisper) │ │ (pyannote.audio) │
│ │ │ │
│ "What was said" │ │ "Who spoke when" │
│ │ │ │
│ • Speech → Text │ │ • Detect speaker │
│ • Word timestamps │ │ turns │
│ • Confidence │ │ • Assign labels │
│ scores │ │ (SPEAKER_00, etc.) │
│ • VAD filtering │ │ • Time boundaries │
│ │ │ │
│ ~40-100ms │ │ ~40-100ms │
│ (live segments) │ │ (live segments) │
└─────────┬──────────┘ └───────────┬───────────┘
│ │
└──────────────┬───────────────────┘
│
▼
┌───────────────────────┐
│ Segment Alignment │
│ │
│ Match transcription │
│ to speaker labels │
│ by timestamp overlap │
└───────────┬───────────┘
│
┌───────────────┴───────────────┐
│ │
▼ ▼
┌────────────────────┐ ┌────────────────────────┐
│ Embedding │ │ Speaker Matching │
│ Extraction │ │ (Cosine Similarity) │
│ (pyannote) │ │ │
│ │ │ Compare embeddings │
│ • Extract voice │──────→ to known speakers │
│ signature │ │ │
│ • 512-D vectors │ │ Threshold: 0.20-0.30 │
│ • Context padding │ │ │
│ (0.15s) │ │ Match or Unknown? │
│ • Skip if <0.5s │ │ │
└────────────────────┘ └───────────┬────────────┘
│
┌──────────────┴──────────────┐
│ │
▼ ▼
┌─────────────────┐ ┌──────────────────┐
│ Known Speaker │ │ Unknown Speaker │
│ "Alice" │ │ "Unknown_01" │
│ │ │ │
│ • Has ID │ │ • No ID yet │
│ • Confidence │ │ • Auto-enrolled │
│ score │ │ • Embedding │
│ │ │ stored │
└────────┬────────┘ └────────┬─────────┘
│ │
└──────────┬────────────────┘
│
▼
┌───────────────────────┐
│ EMOTION DETECTION │
│ (Sequential) │
│ │
│ "How they felt" │
└───────────┬───────────┘
│
┌───────────▼───────────┐
│ Step 1: Speaker │
│ Matching │
│ │
│ • Extract 512-D │
│ voice embedding │
│ • Check ALL profiles:│
│ - Andy (general) │
│ - Andy_angry │
│ - Andy_happy │
│ (if ≥3 samples) │
│ │
│ Returns: │
│ • speaker_name │
│ • matched_emotion │
│ (or None) │
└───────────┬───────────┘
│
┌───────────▼───────────┐
│ Step 2: emotion2vec+ │
│ (ALWAYS RUNS) │
│ │
│ • Extract 1024-D │
│ emotion embedding │
│ • 9 categories │
│ │
│ Returns: │
│ • emotion: "neutral" │
│ • confidence: 0.78 │
│ │
│ ~30ms per segment │
└───────────┬───────────┘
│
┌───────────▼───────────┐
│ Decision: Did Step 1 │
│ find emotion profile?│
└───────┬───────────────┘
│
┌─────────┴─────────┐
YES │ │ NO
▼ ▼
┌────────────────────┐ ┌──────────────────┐
│ FAST PATH │ │ Check profiles? │
│ Override emotion │ │ │
│ │ │ If has profiles │
│ Use Step 1 result │ │ (≥3 samples): │
│ emotion = "angry" │ │ │
│ conf = 0.92 │ │ → Dual-detector │
│ │ │ comparison │
│ Skip comparison │ │ │
│ │ │ Else: │
│ ~0ms (instant) │ │ → Use emotion2vec│
└────────┬───────────┘ └────────┬─────────┘
│ │
│ ┌────────────▼────────────┐
│ │ SLOW PATH: │
│ │ Dual-Detector Compare │
│ │ │
│ │ • emotion2vec match │
│ │ (1024-D) │
│ │ • Voice profile match │
│ │ (512-D, ≥3 samples) │
│ │ │
│ │ Rules: │
│ │ 1. Both agree → Avg │
│ │ 2. neutral → Trust it │
│ │ 3. Voice >85% → Voice │
│ │ 4. Disagree → neutral │
│ │ 5. Else → emotion2vec │
│ │ │
│ │ ~5ms additional │
│ └────────┬────────────────┘
│ │
└───────────────────┘
│
┌──────────────▼─────────────┐
│ Final Emotion │
│ │
│ With detector_breakdown: │
│ • emotion2vec result │
│ • voice profile result │
│ • final decision + reason │
└────────────────────────────┘
│
▼
┌───────────────────────┐
│ Database Storage │
│ │
│ ConversationSegment: │
│ • text │
│ • speaker_name │
│ • speaker_id │
│ • confidence │
│ • emotion_category │
│ • emotion_confidence │
│ • emotion_corrected │
│ • emotion_misidentified│
│ • start/end times │
│ • word-level data │
└───────────┬───────────┘
│
┌───────────────┴───────────────┐
│ │
▼ ▼
┌──────────────────┐ ┌──────────────────────┐
│ Auto-Clustering │ │ User Identifies │
│ │ │ Unknown Speaker │
│ Group similar │ │ │
│ Unknown speakers│ │ "Unknown_01 is Bob" │
│ by embedding │ │ │
│ similarity │ │ → Embedding Merging │
└──────────────────┘ │ → Retroactive │
│ Updates (all │
│ past segments) │
└──────────────────────┘
│
▼
┌──────────────────────┐
│ User Corrects │
│ Emotion │
│ │
│ "Actually angry, │
│ not neutral" │
│ │
│ → Extract & store: │
│ • 1024-D emotion │
│ embedding │
│ • 512-D voice │
│ embedding │
│ → Merge into │
│ SpeakerEmotion │
│ Profile (weighted│
│ averaging) │
│ → Updates: │
│ • Andy_angry │
│ (emotion profile)│
│ • General Andy │
│ (speaker profile)│
│ → If changing │
│ emotion: recalc │
│ OLD profile too │
│ → Confidence = 100% │
│ (manual confirm) │
│ → After 3+ samples: │
│ voice detector │
│ activates! │
└──────────────────────┘
Key Points:
- Parallel Processing: Transcription (Whisper) and Diarization (Pyannote) run simultaneously using ThreadPoolExecutor, achieving ~50% speedup
- Processing Speed (per segment on GPU):
- Transcription + Diarization: ~40-100ms (parallel)
- Alignment + Voice Embedding Extraction: ~20-40ms
- Speaker Matching (checks all profiles including emotion-specific): ~0.5ms
- emotion2vec+ Extraction (ALWAYS runs): ~30ms
- Decision Path:
- Fast path override (if emotion profile matched): ~0ms instant
- Dual-detector comparison (if profiles exist): ~5ms additional
- Fallback to emotion2vec only: ~0ms (already extracted)
- Audio Conversion: Automatic format conversion (MP3→WAV) before processing; live recording saves 48kHz chunks
- Sequential Operations: Alignment → Voice Embedding Extraction (512-D) → Speaker Matching → emotion2vec Extraction (1024-D) → Decision (override or dual-detector or fallback)
- Emotion Detection Flow:
- Speaker matching checks ALL profiles (general + emotion-specific like Andy_angry)
- emotion2vec ALWAYS extracts emotion (runs for every segment)
- IF speaker matched emotion profile → Override emotion2vec (fast path)
- ELSE IF speaker has learned profiles (≥3 samples) → Dual-detector comparison (5 decision rules)
- ELSE → Use emotion2vec result only
- Dual-Detector System: Stores BOTH 1024-D emotion embeddings (emotion2vec) AND 512-D voice embeddings (speaker recognition) per emotion; voice profile detector requires ≥3 samples to activate
- Personalized Learning: User corrections extract and store BOTH embedding types, merge using weighted averaging; changing emotions recalculates BOTH old and new profiles; confidence set to 100% after manual correction
- Why Sequential?: The bottleneck (transcription + diarization) is parallelized. Post-processing (~35ms total) is fast enough that further parallelization adds complexity without meaningful speedup
- Sample Rates: Browser (48kHz) → Whisper/Pyannote (auto-resample) → Emotion2vec (16kHz) → Storage (WAV 48kHz for streaming, MP3 192k for uploads)
Processing Pipeline
Audio Input
- Upload: MP3/WAV files automatically converted and saved to
data/recordings/ - Live: Browser microphone → streaming chunks saved to
data/stream_segments/
- Upload: MP3/WAV files automatically converted and saved to
Parallel Processing (faster than sequential)
- Diarization (pyannote): Detects speaker turns, outputs segments with anonymous labels (SPEAKER_00, SPEAKER_01, etc.)
- Transcription (Whisper): Converts speech to text with timestamps
- Both run simultaneously using ThreadPoolExecutor
Segment Alignment
- Match transcription segments to speaker labels by timestamp overlap
- Uses segment midpoint for matching:
(start + end) / 2 - Falls back to closest segment if no exact overlap
Embedding Extraction
- For each segment, extract 512-dimensional voice signature using pyannote embedding model
- Context padding (0.15s) added before/after for robustness with background noise
- Minimum segment duration: 0.5 seconds
Speaker Matching
- Compare segment embedding to known speaker embeddings
- Cosine similarity calculation (0.0-1.0)
- If similarity > threshold (default 0.30): Identified as known speaker
- If similarity ≤ threshold: Labeled as "Unknown_XX"
Unknown Speaker Handling
- Embedding verification: Check if multiple Unknown segments are the same person
- Group similar unknowns (same threshold)
- Each unique voice gets unique Unknown_XX identifier
- Embeddings stored for future auto-enrollment
Auto-Enrollment (when user identifies unknown)
- User provides speaker name for any segment
- If new name: Creates speaker profile automatically
- Embedding merging: Averages embeddings from all segments of same speaker
- Retroactive updates: All past segments with same Unknown label get updated
- Continuous improvement: Each identification strengthens speaker profile
Voice Activity Detection (VAD)
Two independent VAD systems work together:
Live Recording VAD (energy-based)
- Calculates RMS energy:
sqrt(mean(audio^2)) - Threshold: 0.005 (configurable)
- Detects speech vs. silence in real-time
- Shows live indicator in UI: "🟢 Speech Detected" or "⚪ Idle"
- After X seconds silence (default 0.5s), triggers segment processing
- Calculates RMS energy:
Transcription VAD (Whisper's built-in)
- Uses Silero VAD model
- Filters non-speech before transcription
- Reduces hallucinations ("thank you.", "thanks for watching")
- Enabled via
vad_filter=Trueparameter
Misidentification Correction
- Mark as Misidentified: Exclude segment from embedding calculations
- Reassign to Correct Speaker: Updates both speakers' embeddings
- Automatic Recalculation: Embedding averaged from all non-misidentified segments
- Prevents Embedding Corruption: Ensures speaker profiles remain accurate
REST API & MCP Server
API Overview
Base URL: http://localhost:8000/api/v1Interactive Docs: http://localhost:8000/docs (Swagger UI with test interface)
Key Endpoints:
- System
GET /status- Health check, GPU status, system stats
- Settings
GET/POST /settings/voice- Runtime configuration (thresholds, padding, filtering)POST /settings/voice/reset- Reset to defaults
- Speakers
GET /speakers- List all enrolled speakers with segment countsPOST /speakers/enroll- Enroll new speaker with audio samplePATCH /speakers/{id}/rename- Rename speaker (auto-updates all past segments)DELETE /speakers/{id}- Delete speaker profileDELETE /speakers/unknown/all- Delete all Unknown_* speakers
- Emotion Profiles
GET /speakers/{id}/emotion-profiles- View learned emotion profilesDELETE /speakers/{id}/emotion-profiles- Reset emotion profilesGET/PATCH /speakers/{id}/emotion-threshold- Per-speaker emotion thresholdPATCH /speakers/{id}/emotion-profiles/{emotion}/threshold- Per-emotion threshold
- Conversations
GET /conversations- List all conversations (paginated)GET /conversations/{id}- Get full transcript with all segmentsPATCH /conversations/{id}- Update conversation metadataDELETE /conversations/{id}- Delete conversation and audioPOST /conversations/{id}/reprocess- Re-run diarization with current speakersPOST /conversations/{id}/recalculate-emotions- Recalculate emotions for all segmentsPOST /process- Upload and process audio file
- Segments
POST /conversations/{id}/segments/{seg_id}/identify- Identify speaker (auto-updates all past)POST /conversations/{id}/segments/{seg_id}/correct-emotion- Correct and learn emotionPATCH /conversations/{id}/segments/{seg_id}/misidentified- Mark speaker as misidentifiedPATCH /conversations/{id}/segments/{seg_id}/emotion-misidentified- Mark emotion as wrongGET /conversations/segments/{seg_id}/audio- Download segment audio
- Streaming
WS /streaming/ws- WebSocket for live recording
- Backup/Restore
POST /profiles- Create new backup profileGET /profiles- List all backup profilesGET /profiles/{name}- Get specific profile detailsPATCH /profiles/{name}- Save current state to profileDELETE /profiles/{name}- Delete backup profilePOST /profiles/{name}/checkpoints- Create checkpointPOST /profiles/restore- Restore from backupGET /profiles/download/{name}- Download backup JSONPOST /profiles/import- Import backup JSON
📖 Full documentation with examples: http://localhost:8000/docs
MCP Server Integration
Model Context Protocol (MCP) enables AI assistants to directly interact with the speaker diarization system.
MCP Endpoint: http://localhost:8000/mcpProtocol: JSON-RPC 2.0 over HTTP with Server-Sent EventsCompatible With: Claude Desktop, Flowise, custom MCP clients
Available MCP Tools (11):
list_conversations- Get conversation IDs and metadataget_conversation- Get full transcript with speaker labelsget_latest_segments- Get recent segments across conversationsidentify_speaker_in_segment- Label unknown speaker (auto-updates all past segments)rename_speaker- Rename existing speaker (auto-updates all past segments)list_speakers- Get all enrolled speaker profilesdelete_speaker- Remove speaker profiledelete_all_unknown_speakers- Cleanup Unknown_* speakersupdate_conversation_title- Set conversation titlereprocess_conversation- Re-run recognition with updated speaker profilessearch_conversations_by_speaker- Find all conversations where a specific speaker appears
Key Features:
- Automatic Retroactive Updates: Identifying/renaming a speaker updates ALL past segments automatically
- No Reprocessing Needed: System maintains speaker identity across sessions
- Auto-Enrollment: Can create speaker profiles from any segment
- Conversation Context: AI can retrieve full "who said what" history
Example MCP Client Configuration (Flowise/Claude Desktop):
{
"mcpServers": {
"speaker-diarization": {
"url": "http://localhost:8000/mcp",
"transport": "http"
}
}
}
Usage Example:
# AI assistant receives conversation
Assistant: "I heard multiple voices. Who were you speaking with?"
User: "That was my colleague Sarah"
# AI calls MCP tool:
# identify_speaker_in_segment(segment_id=145, speaker_name="Sarah", auto_enroll=true)
# System automatically:
# 1. Creates Sarah's speaker profile from segment 145
# 2. Updates ALL past segments with Sarah's voice
# 3. Future recordings recognize Sarah automatically
## AI Assistant Integration Examples
Build conversational AI assistants with persistent speaker memory using either REST API or MCP server.
### Integration Approaches
**Option 1: REST API** (Full Control)
- Your app manages audio recording and streaming
- POST audio to `/api/v1/process` or use WebSocket `/streaming/ws`
- Receive segments with speaker labels and emotions
- Query conversation history via `/conversations` endpoints
**Option 2: MCP Server** (AI-Native)
- Connect Claude Desktop, Flowise, or custom MCP clients
- AI assistant directly calls 10 MCP tools for speaker management
- Automatic retroactive updates when identifying/renaming speakers
- Zero code - just configure MCP endpoint
### Example Workflow
**Scenario**: AI assistant having multi-party conversation
1. **Unknown speaker detected**
User: "Alright mate, how are you doing?"Unknown: "Good mate, you?"
AI: "Who are you speaking to?"User: "That's Nick"
2. **AI identifies speaker via MCP**
```python
# MCP tool call (automatic if using Claude/Flowise)
identify_speaker_in_segment(
segment_id=145,
speaker_name="Nick",
auto_enroll=true
)
System auto-updates all past segments
- Creates Nick's voice profile
- Updates ALL previous Unknown segments with Nick's voice
- Future recordings recognize Nick automatically
AI remembers Nick in future conversations
Nick: "Hey, remember what we discussed yesterday?" AI: "Yes Nick, you mentioned the project deadline..."
REST API Quick Start
import requests
# Process audio file
with open("meeting.wav", "rb") as f:
response = requests.post(
"http://localhost:8000/api/v1/process",
files={"audio_file": f}
)
conversation = response.json()
# Get full transcript with speakers
for segment in conversation["segments"]:
print(f"{segment['speaker_name']}: {segment['text']}")
print(f" Emotion: {segment['emotion_category']} ({segment['emotion_confidence']})")
MCP Configuration
Claude Desktop (~/.claude/claude_desktop_config.json):
{
"mcpServers": {
"speaker-diarization": {
"command": "node",
"args": ["/path/to/mcp-proxy.js", "http://localhost:8000/mcp"]
}
}
}
Flowise: Add MCP node, set URL to http://localhost:8000/mcp
Key Benefits
- Persistent Identity: Speakers recognized across all conversations
- Zero Re-enrollment: Identify once, recognized forever
- Retroactive Intelligence: Past segments auto-update when you identify someone
- Emotion Context: AI knows not just "who" but "how" they're feeling
- Production Scale: Handles thousands of conversations with sub-second queries
Advanced Features
Embedding Merging
When identifying unknown speakers or re-identifying existing speakers:
- Never replaces embeddings (would lose historical data)
- Always merges using averaging:
(existing_embedding + new_embedding) / 2 - Continuous improvement: Each recording strengthens speaker profile
- Handles variability: Averages across different audio conditions, emotions, etc.
Retroactive Identification
Rename any speaker → all past segments automatically update:
# User identifies Unknown_01 as "Alice" in conversation 5
curl -X POST "http://localhost:8000/api/v1/conversations/5/segments/123/identify?speaker_name=Alice&enroll=true"
# System automatically:
# 1. Creates "Alice" speaker profile (if new)
# 2. Updates segment 123
# 3. Finds ALL segments with speaker_name="Unknown_01"
# 4. Updates ALL to speaker_name="Alice"
# 5. Merges embeddings from all segments
# 6. Returns count of updated segments
Backup & Restore
Export and restore speaker profiles:
Backup:
- Exports all speakers and their embeddings to JSON
- Includes segment assignments for full state recovery
- Saves to
backups/backup_YYYYMMDD_HHMMSS.json - Does NOT include audio files (only speaker data)
Restore:
- Reconstructs speaker database from backup
- Restores embeddings and segment assignments
- Useful for testing different configurations
- Useful for migrating between deployments
Ground Truth Labeling
Test and optimize recognition accuracy:
- Manually label segments with true speaker identities
- Labels stored separately (doesn't affect actual segments)
- Run tests comparing predictions vs. labels
- Optimize threshold and padding parameters
- Current optimal settings derived from this testing
Data Persistence
Directory Structure
speaker-diarization-app/
├── data/
│ ├── recordings/ # Permanent audio storage
│ │ ├── conv_7_full.mp3 # Live recordings (MP3)
│ │ ├── uploaded_1_tommy_converted.wav # Uploads
│ │ └── 20251109_160230_meeting.wav # Timestamped uploads
│ │
│ ├── stream_segments/ # Live recording segments (temporary)
│ │ └── conv_7/
│ │ ├── seg_0001.wav
│ │ ├── seg_0002.wav
│ │ └── ...
│ │
│ └── temp/ # Temporary segment extractions
│ └── segment_123_456.wav
│
├── volumes/
│ ├── speakers.db # SQLite database
│ └── huggingface_cache/ # Downloaded models
│
├── backups/ # Backup snapshots (JSON)
│ └── backup_20251109_120000.json
│
├── scripts/ # Utility scripts
│ ├── migrate_temp_audio.py # Fix audio paths
│ ├── diagnose_speakers.py # Debug issues
│ └── ...
│
└── tests/ # Test files
└── test_*.py
Docker Volumes
All data persists via volume mounts in docker-compose.yml:
volumes:
- ./volumes:/app/volumes # Database + model cache
- ./data:/app/data # Audio files
- ./backups:/app/backups # Backup snapshots
What Persists:
- ✅ Speaker profiles and embeddings
- ✅ All conversations and segments
- ✅ Audio recordings
- ✅ Downloaded models (~3-5GB)
- ✅ Backup snapshots
What Doesn't Persist:
- ❌ Container state (rebuild-safe)
- ❌ Logs (use
docker-compose logs -fto monitor)
Troubleshooting
Installation Issues
"HuggingFace token not found"
- Ensure
HF_TOKENset in.envfile - Accept model terms at HuggingFace (links in Prerequisites)
- Check token has no extra spaces/quotes
"Unable to load libcudnn_cnn.so.9"
- Standalone:
run_local.shsets LD_LIBRARY_PATH automatically - Docker: Dockerfile installs cuDNN via pip
- Manual:
pip install nvidia-cudnn-cu12==9.* nvidia-cublas-cu12
Permission errors
sudo chown -R $USER:docker data/ volumes/ backups/
Docker GPU not detected
# Verify NVIDIA Container Toolkit installed
docker run --rm --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
# If fails, reinstall NVIDIA Container Toolkit
Processing Issues
"CUDA out of memory"
- Close other GPU applications
- Process shorter audio segments
- Enable transcription selectively (disable for diarization-only)
- Fallback: Run on CPU (set
CUDA_VISIBLE_DEVICES=""- very slow)
Speaker not recognized
- Enrollment audio should be 10-30 seconds minimum
- Use clear audio with minimal background noise
- Check threshold: Lower = more strict (try 0.20-0.35 range, default 0.30)
- Re-enroll with better quality audio
"Audio file not found" errors
- Old uploads: Run
python scripts/migrate_temp_audio.py - New uploads: Should auto-save to
data/recordings/ - Verify
data/directory is accessible
Whisper hallucinations ("thank you.", "thanks for watching")
- Already filtered via energy thresholding and text filtering
- Set
FILTER_HALLUCINATIONS=truein.env - Ensure
vad_filter=Truein transcription (default)
Performance Issues
Slow processing
- Verify GPU in use: Check
nvidia-smiduring processing - Docker: Ensure
runtime: nvidiain docker-compose.yml - Check CUDA available:
python -c "import torch; print(torch.cuda.is_available())" - First run: Models download (~3-5GB), subsequent runs much faster
High memory usage
- Normal: Models load ~4-6GB VRAM
- Transcription adds ~2-3GB
- Multiple simultaneous processes multiply memory usage
- Reduce batch size or process sequentially
Audio Issues
No audio playback in UI
- Check audio files exist:
ls data/recordings/ - Verify API endpoint returns audio:
/api/v1/conversations/segments/{id}/audio - Check browser console for errors
- Try different browser (tested: Chrome, Firefox, Safari)
Live recording not working
- Browser permission: Allow microphone access
- Standalone: Install PortAudio:
sudo apt-get install portaudio19-dev - Check browser microphone settings
- Try different browser
License
This project is licensed under the MIT License - see the LICENSE file for details.
Dependency Licenses
All major dependencies use permissive open-source licenses compatible with MIT:
- pyannote.audio (4.0.1): MIT License
- Models require HuggingFace token and terms acceptance
- Models themselves remain open-source and MIT licensed
- faster-whisper (1.2.1): MIT License (SYSTRAN)
- FastAPI (0.115.5): MIT License
- Next.js (15.x): MIT License
- PyTorch (2.5.1): BSD 3-Clause License
- SQLAlchemy (2.0.36): MIT License
- Pydantic (2.11.0): MIT License
- MCP (1.21.0): MIT License
Note: While the software licenses are permissive, pyannote's pretrained models require:
- HuggingFace account
- Access token
- Acceptance of model terms of use
This is an authentication requirement, not a licensing restriction. The models remain open-source.
Credits
This project builds upon exceptional open-source work:
- pyannote.audio by Hervé Bredin - State-of-the-art speaker diarization and embedding models
- faster-whisper by SYSTRAN - Optimized Whisper implementation using CTranslate2
- OpenAI Whisper - Original speech recognition model
- FastAPI by Sebastián Ramírez - Modern web framework
Thank you to these projects and their contributors for making this application possible.
Planned Features
The following features are planned for future releases:
Automatic Conversation Summarization and Titling
- AI-powered conversation summarization when recording finishes
- Automatic title generation based on conversation content
- Triggers when current conversation ends and new one begins
- Replaces generic "Conversation 15" with meaningful titles like "Discussion about project deadline with Nick"
- Helps with conversation discovery and context retrieval
Vector Database Search for Transcriptions
- Store transcription text in a vector database for semantic search
- Query conversations by topic or content, not just speaker
- Each vector entry references conversation ID for easy retrieval
- Enables long-term memory and contextual conversation lookup
- Use cases:
- "What did we discuss about the budget last month?"
- "Find conversations where we talked about product features"
- "Show me all discussions related to the new project"
Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
Areas for contribution:
- Additional language support (currently English-only)
- Performance optimizations
- UI/UX improvements
- Documentation improvements
Disclaimer
This software is provided "as-is" without warranty of any kind. The developers make no guarantees about the accuracy of speaker identification or transcription. While we've implemented best practices and extensive testing, speaker recognition is inherently probabilistic and may produce errors.
Use responsibly:
- Verify important identifications manually
- Test thoroughly in your environment
- Respect privacy and obtain consent before recording
- This is a tool to assist, not replace, human judgment
Some portions of this codebase were developed collaboratively with Claude Code (AI pair programming assistant). While thoroughly tested, we recommend reviewing code before deploying in critical applications.
Questions or issues? Open an issue on GitHub or check existing issues for solutions.
Want to use this with AI agents? See the API Reference section for MCP integration guidance.